Eino ADK MultiAgent: Supervisor Agent
Supervisor Agent 概述
Import Path
import ``github.com/cloudwego/eino/adk/prebuilt/supervisor
什么是 Supervisor Agent?
Supervisor Agent 是一种中心化多 Agent 协作模式,由一个监督者(Supervisor Agent) 和多个子 Agent(SubAgents)组成。Supervisor 负责任务的分配、子 Agent 执行过程的监控,以及子 Agent 完成后的结果汇总与下一步决策;子 Agent 则专注于执行具体任务,并在完成后通过 WithDeterministicTransferTo 自动将任务控制权交回 Supervisor。
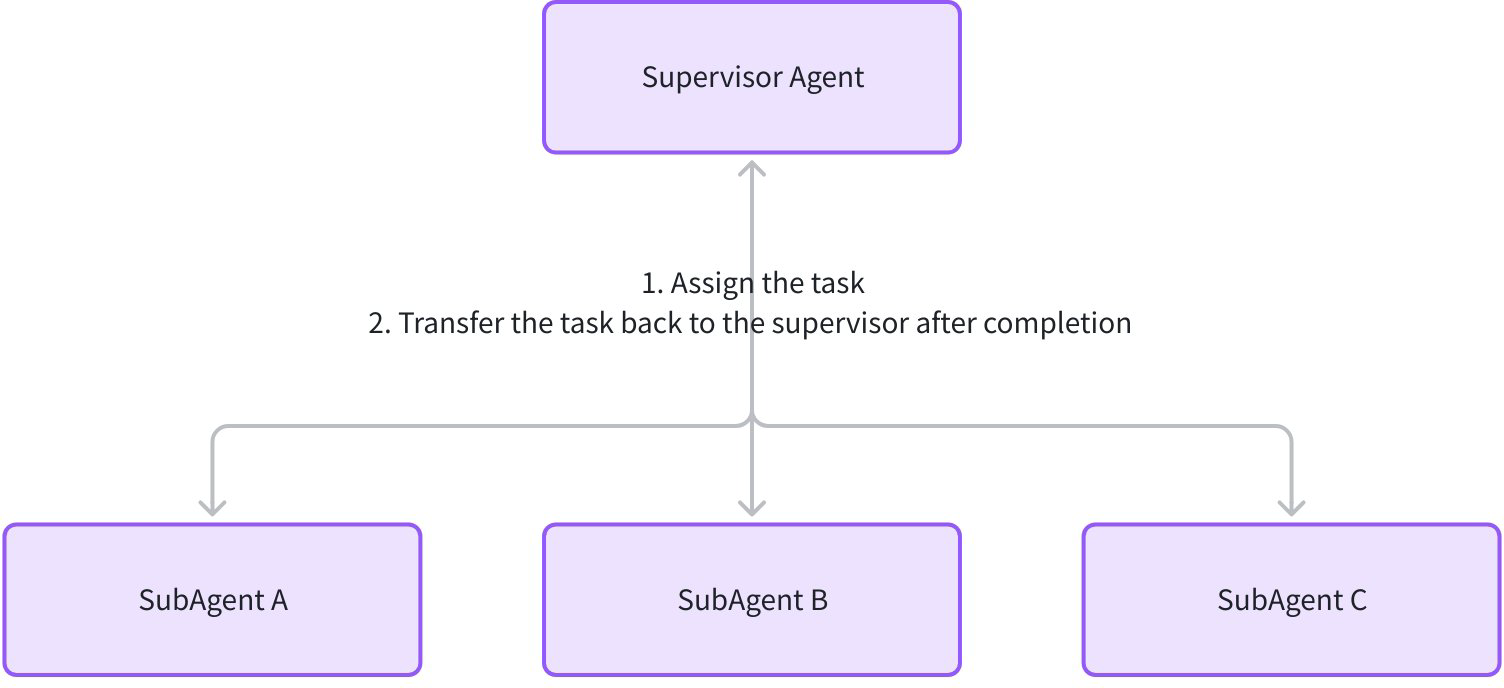
该模式适用于需要动态协调多个专业 Agent 完成复杂任务的场景,例如:
- 科研项目管理(Supervisor 分配调研、实验、报告撰写任务给不同子 Agent)。
- 客户服务流程(Supervisor 根据用户问题类型,分配给技术支持、售后、销售等子 Agent)。
Supervisor Agent 结构
Supervisor 模式的核心结构如下:
- Supervisor Agent:作为协作核心,具备任务分配逻辑(如基于规则或 LLM 决策),可通过
SetSubAgents将子 Agent 纳入管理。 - SubAgents:每个子 Agent 被 WithDeterministicTransferTo 增强,预设
ToAgentNames为 Supervisor 名称,确保任务完成后自动转让回 Supervisor。
Supervisor Agent 特点
- 确定性回调:子 Agent 执行完毕(未中断)后,通过 WithDeterministicTransferTo 自动触发 Transfer 事件,将任务控制权交回 Supervisor,避免协作流程中断。
- 中心化控制:Supervisor 统一管理子 Agent,可根据子 Agent 的执行结果动态调整任务分配(如分配给其他子 Agent 或直接生成最终结果)。
- 松耦合扩展:子 Agent 可独立开发、测试和替换,只需确保实现 Agent 接口并绑定到 Supervisor,即可接入协作流程。
- 支持中断与恢复:若子 Agent 或 Supervisor 支持
ResumableAgent接口,协作流程可在中断后恢复,保持任务上下文连续性。
Supervisor Agent 运行流程
Supervisor 模式的典型协作流程如下:
- 任务启动:Runner 触发 Supervisor 运行,输入初始任务(如“完成一份 LLM 发展历史报告”)。
- 任务分配:Supervisor 根据任务需求,通过 Transfer 事件将任务转让给指定子 Agent(如“调研 Agent”)。
- 子 Agent 执行:子 Agent 执行具体任务(如调研 LLM 关键里程碑),并生成执行结果事件。
- 自动回调:子 Agent 完成后,WithDeterministicTransferTo 触发 Transfer 事件,将任务转让回 Supervisor。
- 结果处理:Supervisor 接收子 Agent 的结果,决定下一步(如分配给“报告撰写 Agent”继续处理,或直接输出最终结果)。
Supervisor Agent 使用示例
场景说明
创建一个科研报告生成系统:
- Supervisor:基于用户输入的研究主题,分配任务给“调研 Agent”和“撰写 Agent”,并汇总最终报告。
- 调研 Agent:负责生成研究计划(如 LLM 发展的关键阶段)。
- 撰写 Agent:负责根据调研计划撰写完整报告。
代码实现
步骤 1:实现子 Agent
首先创建两个子 Agent,分别负责调研和撰写任务:
// 调研 Agent:生成研究计划
func NewResearchAgent(model model.ToolCallingChatModel) adk.Agent {
agent, _ := adk.NewChatModelAgent(context.Background(), &adk.ChatModelAgentConfig{
Name: "ResearchAgent",
Description: "Generates a detailed research plan for a given topic.",
Instruction: `
You are a research planner. Given a topic, output a step-by-step research plan with key stages and milestones.
Output ONLY the plan, no extra text.`,
Model: model,
})
return agent
}
// 撰写 Agent:根据研究计划撰写报告
func NewWriterAgent(model model.ToolCallingChatModel) adk.Agent {
agent, _ := adk.NewChatModelAgent(context.Background(), &adk.ChatModelAgentConfig{
Name: "WriterAgent",
Description: "Writes a report based on a research plan.",
Instruction: `
You are an academic writer. Given a research plan, expand it into a structured report with details and analysis.
Output ONLY the report, no extra text.`,
Model: model,
})
return agent
}
步骤 2:实现 Supervisor Agent
创建 Supervisor Agent,定义任务分配逻辑(此处简化为基于规则:先分配给调研 Agent,再分配给撰写 Agent):
// Supervisor Agent:协调调研和撰写任务
func NewReportSupervisor(model model.ToolCallingChatModel) adk.Agent {
agent, _ := adk.NewChatModelAgent(context.Background(), &adk.ChatModelAgentConfig{
Name: "ReportSupervisor",
Description: "Coordinates research and writing to generate a report.",
Instruction: `
You are a project supervisor. Your task is to coordinate two sub-agents:
- ResearchAgent: generates a research plan.
- WriterAgent: writes a report based on the plan.
Workflow:
1. When receiving a topic, first transfer the task to ResearchAgent.
2. After ResearchAgent finishes, transfer the task to WriterAgent with the plan as input.
3. After WriterAgent finishes, output the final report.`,
Model: model,
})
return agent
}
步骤 3:组合 Supervisor 与子 Agent
使用 NewSupervisor 将 Supervisor 和子 Agent 组合:
import (
"context"
"github.com/cloudwego/eino-ext/components/model/openai"
"github.com/cloudwego/eino/adk"
"github.com/cloudwego/eino/adk/prebuilt/supervisor"
"github.com/cloudwego/eino/components/model"
"github.com/cloudwego/eino/schema"
)
func main() {
ctx := context.Background()
// 1. 创建 LLM 模型(如 GPT-4o)
model, _ := openai.NewChatModel(ctx, &openai.ChatModelConfig{
APIKey: "YOUR_API_KEY",
Model: "gpt-4o",
})
// 2. 创建子 Agent 和 Supervisor
researchAgent := NewResearchAgent(model)
writerAgent := NewWriterAgent(model)
reportSupervisor := NewReportSupervisor(model)
// 3. 组合 Supervisor 与子 Agent
supervisorAgent, _ := supervisor.New(ctx, &supervisor.Config{
Supervisor: reportSupervisor,
SubAgents: []adk.Agent{researchAgent, writerAgent},
})
// 4. 运行 Supervisor 模式
iter := supervisorAgent.Run(ctx, &adk.AgentInput{
Messages: []adk.Message{
schema.UserMessage("Write a report on the history of Large Language Models."),
},
EnableStreaming: true,
})
// 5. 消费事件流(打印结果)
for {
event, ok := iter.Next()
if !ok {
break
}
if event.Output != nil && event.Output.MessageOutput != nil {
msg, _ := event.Output.MessageOutput.GetMessage()
println("Agent[" + event.AgentName + "]:\n" + msg.Content + "\n===========")
}
}
}
运行结果
Agent[ReportSupervisor]:
===========
Agent[ReportSupervisor]:
successfully transferred to agent [ResearchAgent]
===========
Agent[ResearchAgent]:
1. **Scope Definition & Background Research**
- Task: Define "Large Language Model" (LLM) for the report (e.g., size thresholds, key characteristics: transformer-based, large-scale pretraining, general-purpose).
- Task: Identify foundational NLP/AI concepts pre-LLMs (statistical models, early neural networks, word embeddings) to contextualize origins.
- Milestone: 3-day literature review of academic definitions, industry reports, and AI historiographies to finalize scope.
2. **Chronological Periodization**
- Task: Divide LLM history into distinct eras (e.g., Pre-2017: Pre-transformer foundations; 2017-2020: Transformer revolution & early LLMs; 2020-Present: Scaling & mainstream adoption).
- Task: Map key events, models, and breakthroughs per era (e.g., 2017: "Attention Is All You Need"; 2018: GPT-1/BERT; 2020: GPT-3; 2022: ChatGPT; 2023: Llama 2).
- Milestone: 10-day timeline draft with annotated model releases, research papers, and technological shifts.
3. **Key Technical Milestones**
- Task: Deep-dive into critical innovations (transformer architecture, pretraining-fine-tuning paradigm, scaling laws, in-context learning).
- Task: Extract details from seminal papers (authors, institutions, methodologies, performance benchmarks).
- Milestone: 1-week analysis of 5-7 foundational papers (e.g., Vaswani et al. 2017; Radford et al. 2018; Devlin et al. 2018) with technical summaries.
4. **Stakeholder Mapping**
- Task: Identify key organizations (OpenAI, Google DeepMind, Meta AI, Microsoft Research) and academic labs (Stanford, Berkeley) driving LLM development.
- Task: Document institutional contributions (e.g., OpenAI’s GPT series, Google’s BERT/PaLM, Meta’s Llama) and research priorities (open vs. closed models).
- Milestone: 5-day stakeholder profile draft with org-specific timelines and model lineages.
5. **Technical Evolution & Innovation Trajectory**
- Task: Analyze shifts in architecture (from RNNs/LSTMs to transformers), training paradigms (pretraining + fine-tuning → instruction tuning → RLHF), and compute scaling (parameters, data size, GPU usage over time).
- Task: Link technical changes to performance improvements (e.g., GPT-1 (124M params) vs. GPT-4 (100B+ params): task generalization, emergent abilities).
- Milestone: 1-week technical trajectory report with data visualizations (param scaling, benchmark scores over time).
6. **Impact & Societal Context**
- Task: Research LLM impact on NLP tasks (translation, summarization, QA) and beyond (education, content creation, policy).
- Task: Document cultural/industry shifts (rise of prompt engineering, "AI-native" products, public perception post-ChatGPT).
- Milestone: 5-day impact analysis integrating case studies (e.g., GitHub Copilot, healthcare LLMs) and media/scholarly discourse.
7. **Challenges & Critiques (Historical Perspective)**
- Task: Track historical limitations (pre-2020: data sparsity, task specificity; post-2020: bias, misinformation, energy use) and responses (e.g., 2019: BERT bias audits; 2023: EU AI Act).
- Task: Cite key critiques (e.g., "On the Dangers of Stochastic Parrots," 2021) and industry/academic reactions.
- Milestone: 5-day challenge timeline linking issues to their emergence and mitigation efforts.
8. **Synthesis & Narrative Drafting**
- Task: Integrate chronological, technical, and societal data into a coherent narrative (origins → revolution → scaling → mainstream impact).
- Task: Outline report structure (Abstract, Introduction, Era-by-Era Analysis, Key Innovations, Stakeholders, Impact, Challenges, Conclusion).
- Milestone: 1-week first draft of full report (8,000–10,000 words).
9. **Validation & Fact-Checking**
- Task: Verify model release dates, paper citations, parameter counts, and stakeholder claims via primary sources (original papers, official press releases, archived GitHub repos).
- Task: Cross-check with secondary sources (AI history books, expert interviews, peer-reviewed historiographies).
- Milestone: 3-day validation report flagging/correcting inaccuracies.
10. **Finalization & Revision**
- Task: Edit for clarity, narrative flow, and consistency; refine visuals (timelines, param scaling charts).
- Task: Format references (APA/MLA) and appendices (model comparison table, key paper list).
- Milestone: 2-day final report submission.
===========
Agent[ResearchAgent]:
===========
Agent[ResearchAgent]:
successfully transferred to agent [ReportSupervisor]
===========
Agent[ReportSupervisor]:
===========
Agent[ReportSupervisor]:
successfully transferred to agent [WriterAgent]
===========
Agent[WriterAgent]:
# The History of Large Language Models: From Foundations to Mainstream Revolution
## Abstract
Large Language Models (LLMs) represent one of the most transformative technological innovations of the 21st century, enabling machines to understand, generate, and manipulate human language with unprecedented fluency. This report traces the historical trajectory of LLMs, from their conceptual roots in early natural language processing (NLP) to their current status as mainstream tools. It examines key technical milestones—including the invention of the transformer architecture, the rise of pretraining-fine-tuning paradigms, and the scaling of model parameters—and contextualizes these within the contributions of academic labs and tech giants. The report also analyzes societal impacts, from revolutionizing NLP tasks to sparking debates over bias, misinformation, and AI regulation. By synthesizing chronological, technical, and cultural data, this history reveals how LLMs evolved from niche research experiments to agents of global change.
## 1. Introduction: Defining Large Language Models
A **Large Language Model (LLM)** is a type of machine learning model designed to process and generate human language by learning patterns from massive text datasets. Key characteristics include: (1) a transformer-based architecture, enabling parallel processing of text sequences; (2) large-scale pretraining on diverse corpora (e.g., books, websites, articles); (3) general-purpose functionality, allowing adaptation to tasks like translation, summarization, or dialogue without task-specific engineering; and (4) scale, typically defined by billions (or tens of billions) of parameters (adjustable weights that capture linguistic patterns).
LLMs emerged from decades of NLP research, building on foundational concepts like statistical models (e.g., n-grams), early neural networks (e.g., recurrent neural networks [RNNs]), and word embeddings (e.g., Word2Vec, GloVe). By the 2010s, these predecessors had laid groundwork for "language understanding," but were limited by task specificity (e.g., a model trained for translation could not summarize text) and data sparsity. LLMs addressed these gaps by prioritizing scale, generality, and architectural innovation—ultimately redefining the boundaries of machine language capability.
## 2. Era-by-Era Analysis: The Evolution of LLMs
### 2.1 Pre-2017: Pre-Transformer Foundations (1950s–2016)
The roots of LLMs lie in mid-20th-century NLP, when researchers first sought to automate language tasks. Early efforts relied on rule-based systems (e.g., 1950s machine translation using syntax rules) and statistical methods (e.g., 1990s n-gram models for speech recognition). By the 2010s, neural networks gained traction: RNNs and long short-term memory (LSTM) models (Hochreiter & Schmidhuber, 1997) enabled sequence modeling, while word embeddings (Mikolov et al., 2013) represented words as dense vectors, capturing semantic relationships.
Despite progress, pre-2017 models faced critical limitations: RNNs/LSTMs processed text sequentially, making them slow to train and unable to handle long-range dependencies (e.g., linking "it" in a sentence to a noun paragraphs earlier). Data was also constrained: models like Word2Vec trained on millions, not billions, of tokens. These bottlenecks set the stage for a paradigm shift.
### 2.2 2017–2020: The Transformer Revolution and Early LLMs
The year 2017 marked the dawn of the LLM era with the publication of *"Attention Is All You Need"* (Vaswani et al.), which introduced the **transformer architecture**. Unlike RNNs, transformers use "self-attention" mechanisms to weigh the importance of different words in a sequence simultaneously, enabling parallel computation and capturing long-range dependencies. This breakthrough reduced training time and improved performance on language tasks.
#### Key Models and Breakthroughs:
- **2018**: OpenAI released **GPT-1** (Radford et al.), the first transformer-based LLM. With 124 million parameters, it introduced the "pretraining-fine-tuning" paradigm: pretraining on a large unlabeled corpus (BooksCorpus) to learn general language patterns, then fine-tuning on task-specific labeled data (e.g., sentiment analysis).
- **2018**: Google published **BERT** (Devlin et al.), a bidirectional transformer that processed text from left-to-right *and* right-to-left, outperforming GPT-1 on context-dependent tasks like question answering. BERT’s success popularized "contextual embeddings," where word meaning depends on surrounding text (e.g., "bank" as a financial institution vs. a riverbank).
- **2019**: OpenAI scaled up with **GPT-2** (1.5 billion parameters), demonstrating improved text generation but sparking early concerns about misuse (OpenAI initially delayed full release over fears of disinformation).
- **2020**: Google’s **T5** (Text-to-Text Transfer Transformer) unified NLP tasks under a single "text-to-text" framework (e.g., translating "translate English to French: Hello" to "Bonjour"), simplifying model adaptation.
### 2.3 2020–Present: Scaling, Emergence, and Mainstream Adoption
The 2020s saw LLMs transition from research curiosities to global phenomena, driven by exponential scaling of parameters, data, and compute.
#### Key Developments:
- **2020**: OpenAI’s **GPT-3** (175 billion parameters) marked a turning point. Trained on 45 terabytes of text, it exhibited "few-shot" and "zero-shot" learning—adapting to tasks with minimal examples (e.g., "Write a poem about AI" with no prior poetry training). GPT-3’s release via API (OpenAI Playground) introduced LLMs to developers, enabling early applications like chatbots and code generation.
- **2022**: **ChatGPT** (based on GPT-3.5) brought LLMs to the public. Launched in November, its user-friendly interface and conversational ability sparked a viral explosion (100 million users by January 2023). ChatGPT refined training with **Reinforcement Learning from Human Feedback (RLHF)**, aligning outputs with human preferences (e.g., helpfulness, safety).
- **2023**: Meta released **Llama 2** (7B–70B parameters), an open-source LLM that lowered barriers to entry, allowing researchers and startups to fine-tune models without proprietary access. Meanwhile, OpenAI’s **GPT-4** (100B+ parameters) expanded multimodality (text + images) and improved reasoning (e.g., solving math problems, coding).
- **2023–2024**: The "race to scale" continued with models like Google’s **PaLM 2** (540B parameters), Anthropic’s **Claude 2** (200B+ parameters), and open-source alternatives (e.g., Mistral, Falcon). Compute usage skyrocketed: training GPT-3 required ~3.14e23 floating-point operations (FLOPs), equivalent to 355 years of a single GPU’s work.
## 3. Key Technical Milestones
### 3.1 The Transformer Architecture (2017)
Vaswani et al.’s *"Attention Is All You Need"* (Google, University of Toronto) replaced RNNs with self-attention, a mechanism that computes "attention scores" between every pair of words in a sequence. For example, in "The cat sat on the mat; it purred," self-attention links "it" to "cat." This parallel processing reduced training time from weeks (for RNNs) to days, enabling larger models.
### 3.2 Pretraining-Fine-Tuning Paradigm (2018)
GPT-1 and BERT established the now-standard workflow: (1) Pretrain on a large, unlabeled corpus (e.g., Common Crawl, a web scrape of 1.1 trillion tokens) to learn syntax, semantics, and world knowledge; (2) Fine-tune on task-specific data (e.g., GLUE, a benchmark of 10 NLP tasks). This decoupled language learning from task engineering, enabling generalization.
### 3.3 Scaling Laws and Emergent Abilities (2020s)
In 2020, OpenAI researchers articulated **scaling laws**: model performance improves predictably with increased parameters, data, and compute. By 2022, this led to "emergent abilities"—skills not present in smaller models, such as GPT-3’s in-context learning or GPT-4’s multi-step reasoning.
### 3.4 Instruction Tuning and RLHF (2022)
Post-2020, training shifted from task-specific fine-tuning to **instruction tuning** (training on natural language instructions like "Summarize this article") and **RLHF** (rewarding models for human-preferred outputs). These methods made LLMs more usable: ChatGPT, for instance, follows prompts like "Explain quantum physics like I’m 5" without explicit fine-tuning.
## 4. Stakeholders: The Ecosystem of LLM Development
LLM evolution has been driven by a mix of tech giants, academic labs, and startups, each with distinct priorities:
### 4.1 Tech Giants: Closed vs. Open Models
- **OpenAI** (founded 2015, backed by Microsoft): Pioneered the GPT series, prioritizing commercialization via closed APIs (e.g., ChatGPT Plus, GPT-4 API). Focus: user-friendliness and safety (via RLHF).
- **Google DeepMind**: Developed BERT, T5, and PaLM, integrating LLMs into products like Google Search (via BERT) and Bard. Balances closed (PaLM) and open (T5) models.
- **Meta AI**: Advocated for open science with Llama 1/2 (2023), releasing weights for research and commercial use. Meta’s "open" approach aims to democratize LLM access and accelerate safety research.
- **Microsoft**: Partnered with OpenAI (2019–present), providing Azure compute and integrating GPT into Bing (search), Office (Copilot), and GitHub (Copilot X for coding).
### 4.2 Academic Labs
- **Stanford NLP**: Contributed to BERT and T5 research; developed HELM (Holistic Evaluation of Language Models), a benchmark for LLM safety and fairness.
- **UC Berkeley**: Studied LLM bias (e.g., 2021 paper "On the Dangers of Stochastic Parrots," critiquing LLMs as "statistical mimics" lacking true understanding).
## 5. Impact & Societal Context
### 5.1 Transforming NLP and Beyond
LLMs have redefined NLP performance: By 2023, GPT-4 outperformed humans on the MMLU benchmark (a test of 57 subjects, including math, law, and biology), scoring 86.4% vs. 86.5% for humans. Beyond NLP, they have revolutionized:
- **Content Creation**: Tools like Jasper and Copy.ai automate marketing copy; artists use DALL-E (paired with LLMs) for text-to-image generation.
- **Education**: Khan Academy’s Khanmigo tutors students; Coursera uses LLMs for personalized feedback.
- **Coding**: GitHub Copilot (2021) generates code from comments, boosting developer productivity by 55% (Microsoft, 2023).
### 5.2 Cultural Shifts
- **Prompt Engineering**: The rise of "prompt engineers"—professionals skilled in crafting text inputs to elicit desired LLM outputs—became a new career path.
- **AI-Native Products**: Startups like Character.AI (chatbots with distinct personalities) and Perplexity (AI-powered search) emerged as "LLM-first" services.
- **Public Perception**: Post-ChatGPT, LLMs shifted from "AI hype" to tangible utility, though skepticism persists (e.g., 62% of U.S. adults worry about job displacement, Pew Research, 2023).
## 6. Challenges & Critiques: A Historical Perspective
### 6.1 Technical Limitations
- **Pre-2020**: Data sparsity (small corpora limited generalization); task specificity (models like BERT required retraining for new tasks).
- **Post-2020**: **Hallucinations** (fabricating facts, e.g., GPT-3 citing fake research papers); **energy use** (training GPT-3 emitted ~500 tons of CO₂, equivalent to 125 round-trip flights from NYC to London); **computational inequality** (only tech giants can afford 100B+ parameter models).
### 6.2 Societal Risks
- **Bias**: Early LLMs mirrored training data biases (e.g., BERT associated "doctor" with "male" in 2019 audits). Responses included bias mitigation datasets (e.g., WinoBias) and audits (e.g., Stanford’s Gender Shades).
- **Misinformation**: GPT-2’s realistic text generation prompted calls for regulation; by 2023, deepfakes (e.g., AI-generated political speeches) became a policy focus.
- **Regulation**: The EU AI Act (2024) classified LLMs as "high-risk," requiring transparency (e.g., disclosing AI-generated content) and safety testing.
## 7. Conclusion: A Revolution in Five Years
The history of LLMs is a story of exponential progress: from the transformer’s 2017 invention to ChatGPT’s 2022 viral explosion, a mere five years. What began as an academic breakthrough—parallelizing text processing with self-attention—evolved into a technology that writes code, tutors students, and shapes global policy.
Yet challenges persist: scaling has outpaced our understanding of how LLMs "think," and debates over bias, energy use, and access (closed vs. open models) intensify. As we look to the future, this history reminds us that LLMs are not just technical achievements, but mirrors of society—reflecting both our ingenuity and our flaws. Their next chapter will depend on balancing innovation with responsibility, ensuring these models serve as tools for collective progress.
## References
- Devlin, J., et al. (2018). *BERT: Pre-training of deep bidirectional transformers for language understanding*. NAACL.
- Hochreiter, S., & Schmidhuber, J. (1997). *Long short-term memory*. Neural Computation.
- Mikolov, T., et al. (2013). *Efficient estimation of word representations in vector space*. ICLR.
- Radford, A., et al. (2018). *Improving language understanding by generative pre-training*. OpenAI.
- Vaswani, A., et al. (2017). *Attention is all you need*. NeurIPS.
- Weidinger, L., et al. (2021). *On the dangers of stochastic parrots: Can language models be too big?*. ACM FAccT.
===========
Agent[WriterAgent]:
===========
Agent[WriterAgent]:
successfully transferred to agent [ReportSupervisor]
===========
WithDeterministicTransferTo
什么是 WithDeterministicTransferTo?
WithDeterministicTransferTo 是 Eino ADK 提供的 Agent 增强工具,用于为 Agent 注入任务转让(Transfer)能力 。它允许开发者为目标 Agent 预设固定的任务转让路径,当该 Agent 完成任务(未被中断)时,会自动生成 Transfer 事件,将任务流转到预设的目标 Agent。
这一能力是构建 Supervisor Agent 协作模式的基础,确保子 Agent 在执行完毕后能可靠地将任务控制权交回监督者(Supervisor),形成“分配-执行-反馈”的闭环协作流程。
WithDeterministicTransferTo 核心实现
配置结构
通过 DeterministicTransferConfig 定义任务转让的核心参数:
// 包装方法
func AgentWithDeterministicTransferTo(_ context.Context, config *DeterministicTransferConfig) Agent
// 配置详情
type DeterministicTransferConfig struct {
Agent Agent // 被增强的目标 Agent
ToAgentNames []string // 任务完成后转让的目标 Agent 名称列表
}
Agent:需要添加转让能力的原始 Agent。ToAgentNames:当Agent完成任务且未中断时,自动转让任务的目标 Agent 名称列表(按顺序转让)。
Agent 包装
WithDeterministicTransferTo 会对原始 Agent 进行包装,根据其是否实现 ResumableAgent 接口(支持中断与恢复),分别返回 agentWithDeterministicTransferTo 或 resumableAgentWithDeterministicTransferTo 实例,确保增强能力与 Agent 原有功能(如 Resume 方法)兼容。
包装后的 Agent 会覆盖 Run 方法(对 ResumableAgent 还会覆盖 Resume 方法),在原始 Agent 的事件流基础上追加 Transfer 事件:
// 对普通 Agent 的包装
type agentWithDeterministicTransferTo struct {
agent Agent // 原始 Agent
toAgentNames []string // 目标 Agent 名称列表
}
// Run 方法:执行原始 Agent 任务,并在任务完成后追加 Transfer 事件
func (a *agentWithDeterministicTransferTo) Run(ctx context.Context, input *AgentInput, options ...AgentRunOption) *AsyncIterator[*AgentEvent] {
aIter := a.agent.Run(ctx, input, options...)
iterator, generator := NewAsyncIteratorPair[*AgentEvent]()
// 异步处理原始事件流,并追加 Transfer 事件
go appendTransferAction(ctx, aIter, generator, a.toAgentNames)
return iterator
}
对于 ResumableAgent,额外实现 Resume 方法,确保恢复执行后仍能触发确定性转让:
type resumableAgentWithDeterministicTransferTo struct {
agent ResumableAgent // 支持恢复的原始 Agent
toAgentNames []string // 目标 Agent 名称列表
}
// Resume 方法:恢复执行原始 Agent 任务,并在完成后追加 Transfer 事件
func (a *resumableAgentWithDeterministicTransferTo) Resume(ctx context.Context, info *ResumeInfo, opts ...AgentRunOption) *AsyncIterator[*AgentEvent] {
aIter := a.agent.Resume(ctx, info, opts...)
iterator, generator := NewAsyncIteratorPair[*AgentEvent]()
go appendTransferAction(ctx, aIter, generator, a.toAgentNames)
return iterator
}
事件流追加 Transfer 事件
appendTransferAction 是实现确定性转让的核心逻辑,它会消费原始 Agent 的事件流,在 Agent 任务正常结束(未中断)后,自动生成并发送 Transfer 事件到目标 Agent:
func appendTransferAction(ctx context.Context, aIter *AsyncIterator[*AgentEvent], generator *AsyncGenerator[*AgentEvent], toAgentNames []string) {
defer func() {
// 异常处理:捕获 panic 并通过事件传递错误
if panicErr := recover(); panicErr != nil {
generator.Send(&AgentEvent{Err: safe.NewPanicErr(panicErr, debug.Stack())})
}
generator.Close() // 事件流结束,关闭生成器
}()
interrupted := false
// 1. 转发原始 Agent 的所有事件
for {
event, ok := aIter.Next()
if !ok { // 原始事件流结束
break
}
generator.Send(event) // 转发事件给调用方
// 检查是否发生中断(如 InterruptAction)
if event.Action != nil && event.Action.Interrupted != nil {
interrupted = true
} else {
interrupted = false
}
}
// 2. 若未中断且存在目标 Agent,生成 Transfer 事件
if !interrupted && len(toAgentNames) > 0 {
for _, toAgentName := range toAgentNames {
// 生成转让消息(系统提示 + Transfer 动作)
aMsg, tMsg := GenTransferMessages(ctx, toAgentName)
// 发送系统提示事件(告知用户任务转让)
aEvent := EventFromMessage(aMsg, nil, schema.Assistant, "")
generator.Send(aEvent)
// 发送 Transfer 动作事件(触发任务转让)
tEvent := EventFromMessage(tMsg, nil, schema.Tool, tMsg.ToolName)
tEvent.Action = &AgentAction{
TransferToAgent: &TransferToAgentAction{
DestAgentName: toAgentName, // 目标 Agent 名称
},
}
generator.Send(tEvent)
}
}
}
关键逻辑:
- 事件转发:原始 Agent 产生的所有事件(如思考、工具调用、输出结果)会被完整转发,确保业务逻辑不受影响。
- 中断检查:若 Agent 执行过程中被中断(如
InterruptAction),则不触发 Transfer(中断视为任务未正常完成)。 - Transfer 事件生成:任务正常结束后,为每个
ToAgentNames生成两条事件:- 系统提示事件(
schema.Assistant角色):告知用户任务将转让给目标 Agent。 - Transfer 动作事件(
schema.Tool角色):携带TransferToAgentAction,触发 ADK 运行时将任务转让给DestAgentName对应的 Agent。
- 系统提示事件(
总结
WithDeterministicTransferTo 为 Agent 提供了可靠的任务转让能力,是构建 Supervisor 模式的核心基石;而 Supervisor 模式通过中心化协调与确定性回调,实现了多 Agent 之间的高效协作,显著降低了复杂任务的开发与维护成本。结合两者,开发者可快速搭建灵活、可扩展的多 Agent 系统。