内存泄漏自查手册
框架会帮助用户创建 Request/Response 对象,而如果用户持续持有这些对象不释放,就会导致出现内存持续上涨的现象。但 go pprof heap 只会展示这些泄漏的对象是由谁创建的,并不会统计这些对象由谁在持有。用户可能认为框架在内存泄漏,但实际上不是由于框架导致的。
本文档主要帮助用户先做一次自查,确定内存泄漏点。如果不满足本文档的例子,请在 Github 对应项目仓库提交 Issue,社区维护者会及时跟进处理。
如何看 Go pprof heap
已经了解的用户可以跳过。
查看哪个函数创建了最多内存 -
alloc_space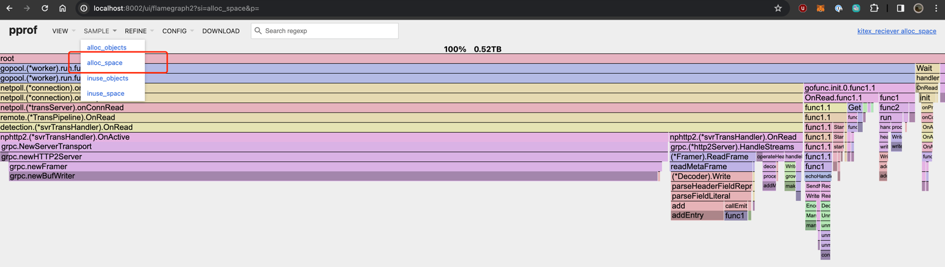
查看哪个函数创建了最多对象 -
alloc_objects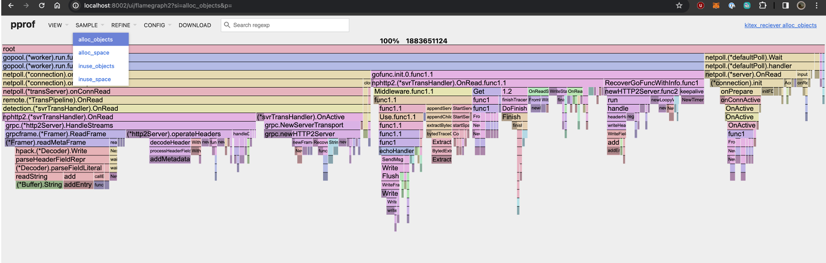
查看哪个函数创建了最多内存的持久对象 -
inuse_space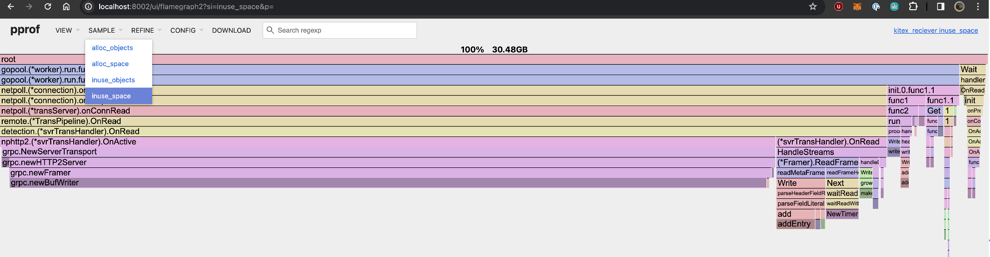
Pprof heap 的原理和坑
Go pprof heap 的实现原理是,每次 malloc/free 的时,插入一些代码,并回溯当前 stacktrace ,从而判断每个函数创建(alloc)和释放(free)了多少内存,进而算出 inuse=(alloc-free)。
大部分情况下这个逻辑都没有什么问题,但是其实 Netpoll 和 Kitex 里有一大堆内存复用,也就是「真正从 Pool 中申请了对象的函数,实际上并没有负责创建对象」。所以你是不会看到这部分被统计在 pprof heap 里的。
但业务逻辑一般很少搞这种操作,不影响分析绝大部分cases。
Server 内存泄漏
连接数突增 + 大包场景导致
过去 Netpoll 内部有一个 barriers 变量会跨连接临时存储一些 buffer ,如果连接突增,会导致其扩容,而后在其中残留历史连接的 buffer 引用,从而出现内存泄漏的情况。
在 netpoll v0.2.5 版本中修复,升级 Kitex >= v0.3.3 即可。
严格来说,即便是小包也会有一些泄漏情况,但是并不明显(1w 连接,每个1kb,仅只有10MB泄漏),所以一般无法发现也没有危害。大包情况下且曾经创建过大量连接时,这个泄漏会更加明显。
典型 profile 现象
- Server Request 泄漏:接受的请求体积较大

- Server Response 泄漏:若返回某字段支持 NoCopy 序列化,则会显示内存创建在业务 handler 中

- Server Response 泄漏:若返回某字段不支持 NoCopy 序列化:会显示内存创建在序列化过程中
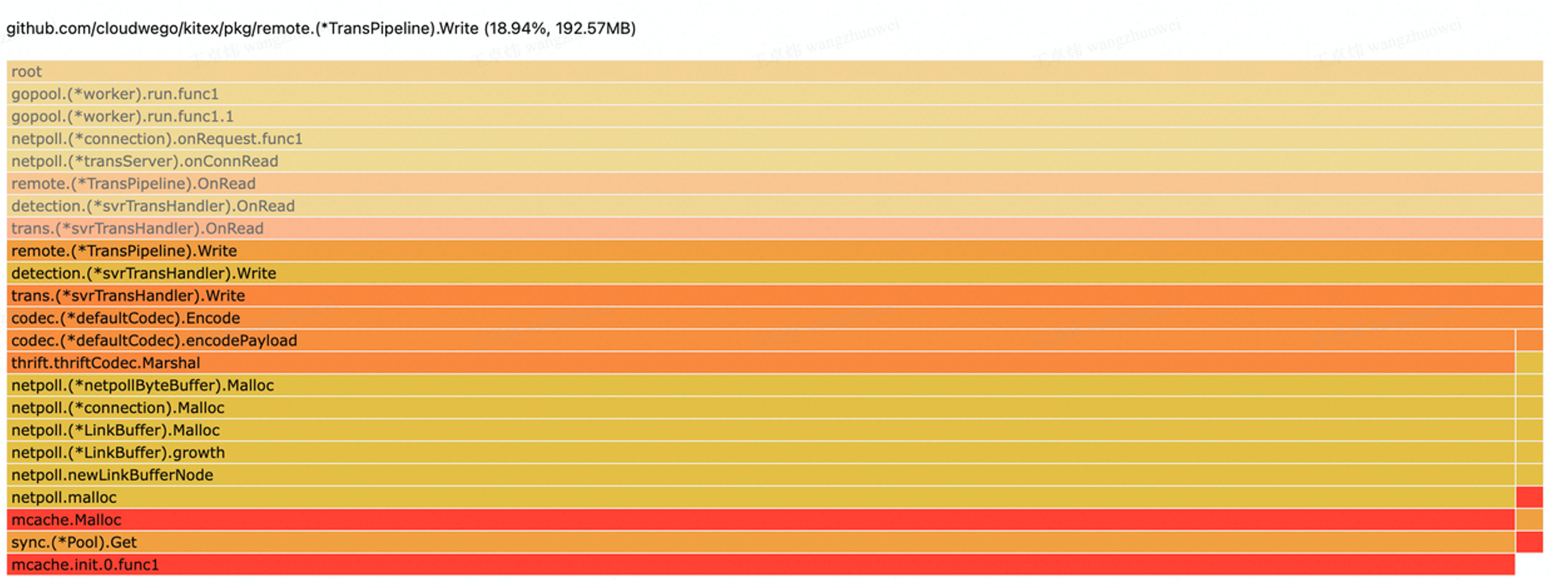
持续持有 Request 的某个字段
典型代码:
注意,对于
[]byte类型或者string类型,即便只是持有某个对象的部分切片,也会导致底层整段内存存在引用
func (s *EchoServerImpl) Echo(ctx context.Context, req *echo.Request) (*echo.Response, error) {
// memory leak
cache.Store(req.Id, req.Msg[:1])
resp := &echo.Response{}
return resp, nil
}
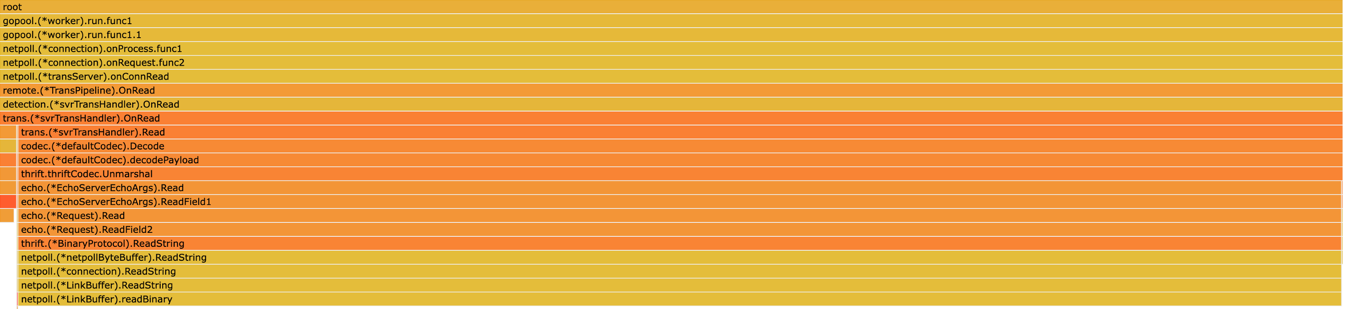
顺着上面的 stack ,可以看到是 Request.Field2 存在内存泄漏,然后去 IDL 里看标号为 2 的 field 是哪个,再去代码里查找泄漏点。
创建过多空闲连接
Netpoll 会给每个连接创建一块初始大小的 buffer,如果上游不停创建连接,就会让下游看起来内存被 netpoll 占满了。
超大包请求
首先确认是否 github.com/cloudwego/netpoll >= v0.2.5 或者 Kitex >=v0.3.3 。如果不是,有可能是前面说的连接数突增导致的 bug。
严格来说,这种情况并不算是内存泄漏,但是 netpoll 会为这些异常大小的请求缓存(sync.Pool)一些内存,所以内存会出现上升。即便不缓存,这种异常大小请求本身就会需要占用很大内存,存在风险。
典型 profile:

常见情况:
- 上游某个字段出现异常的大小
- 上游/或上游的上游透传了超大的值,比如有些业务喜欢透传大体积的 debug info,或者利用透传实现不需要 IDL 定义的需求。
解决方案:通过抓包找出异常大小的请求来源,让对方修改这类用法。
Client 内存泄漏
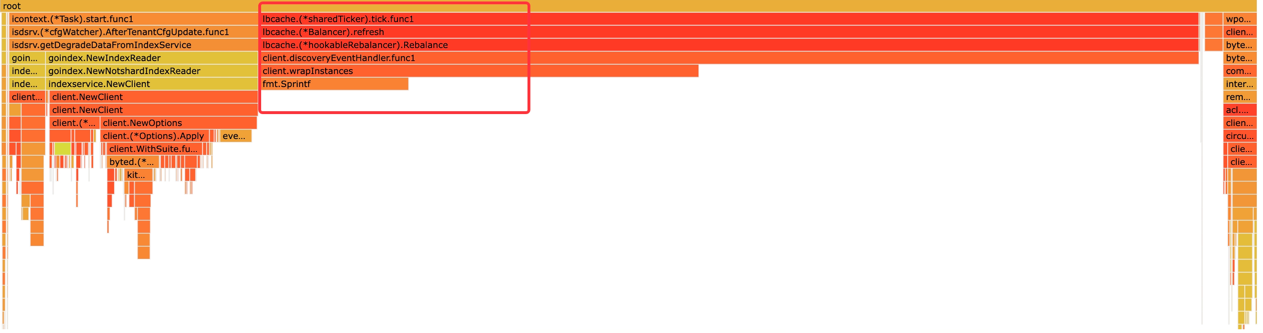
大量 lbcache 的内存占用
lbcache 对每个 client 只会创建一次,如果出现大量 lbcache 的泄漏,说明大概率存在大量重复创建 Client 的行为。
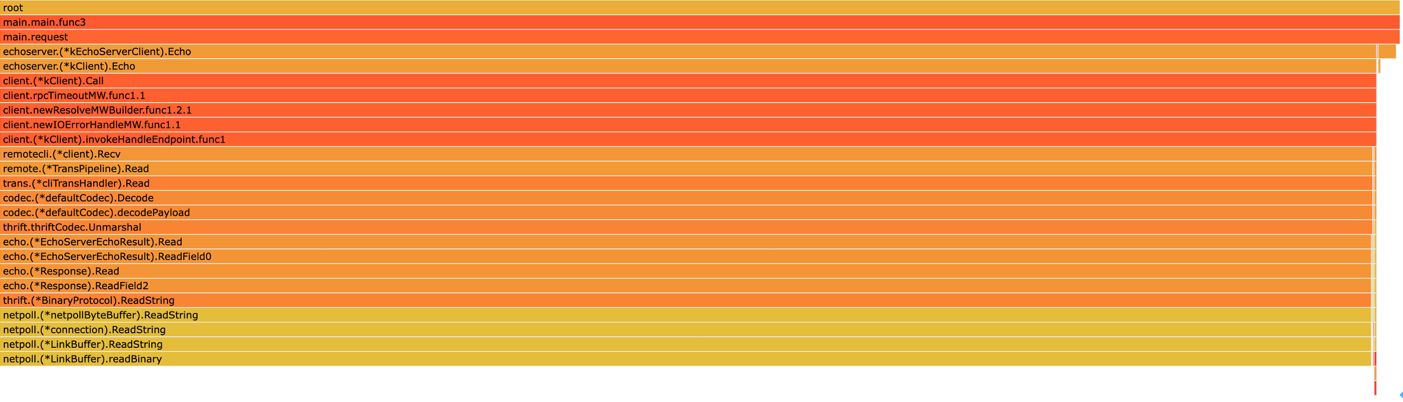
持续持有 Response 的某个字段
典型代码:对 response 某个字段持续存在引用,哪怕只是一个字节的引用。
resp, err := cli.Echo(context.Background(), req)
if err != nil {
return
}
cache.Store(resp.Id, resp.Msg[:1])
使用 Sonic 解析 Request/Response 的 string 字段并“缓存”对象
典型 Profile:
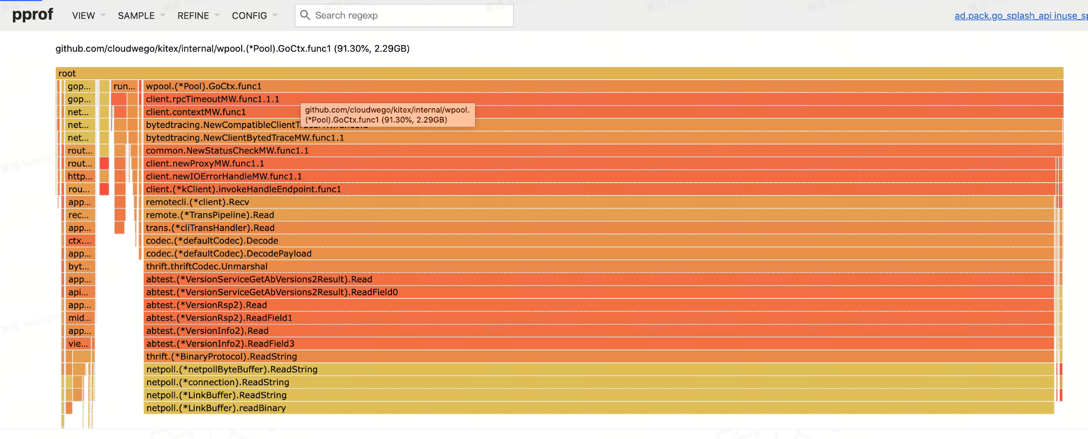
典型触发场景:
Request/Response中有一个大string对象- 使用 Sonic unmarshal 这个
string对象
解决方案:开启 Sonic 的 CopyString 选项。
问题原因:
- Sonic 出于性能考虑,对 unmarshal 后的
string对象会重用传入string的底层内存。如果服务是用来解析大 JSON,并且 缓存该解析对象 或 较多goroutine持有该解析对象 ,可能会导致原始传入的string对象内存长期无法释放,详见 Sonic Request中的内存分配都是在 netpoll 的函数栈中进行的,所以看上去都是 netpoll 创建的对象在内存泄漏。实际上和 netpoll 无关。
当然真正的根因还是在业务代码中有一处地方长期持有了 sonic unmarshal 后的对象。这里只是放大了泄漏的影响,该解决方法也只是减少泄漏的影响。
如果这么操作后还有内存泄漏,那得真正阅读业务代码哪里在长期持有对象了。