Eino 流式编程要点
💡 建议先看:Eino: 基础概念介绍 Eino: 编排的设计理念
编排流式概述
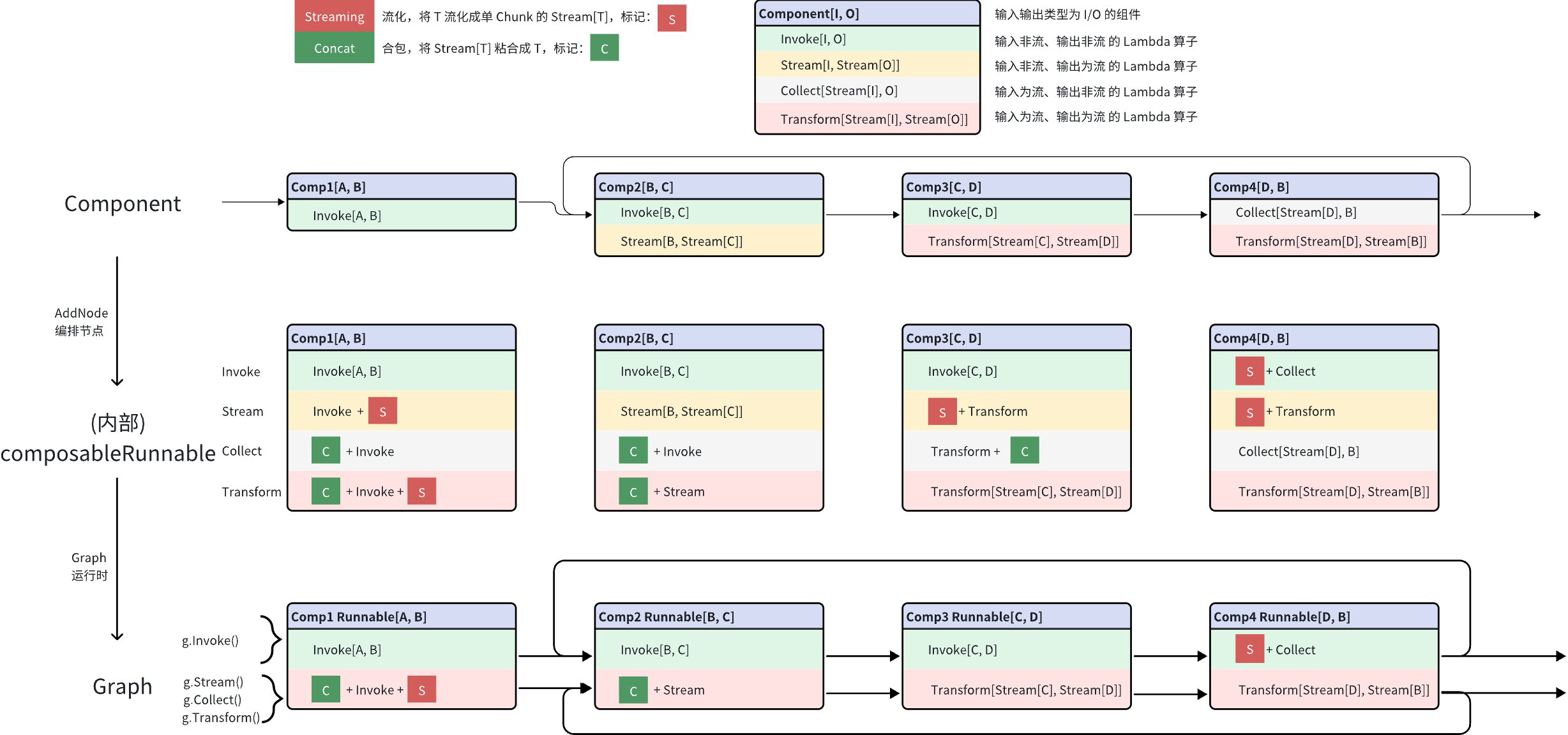
编排流式的 Graph 时,需要考虑的几个关键要素:
- 组件/Lambda 中包含哪几种 Lambda 算子: 从 Invoke、Stream、Collect、Transform 中任选
- 编排拓扑图中,上下游节点的输入、输出是否同为流或同为非流。
- 如果上下游节点的流类型无法匹配。 需要借助 流化、合包 两个操作
- 流化(Streaming):将 T 流化成单 Chunk 的 Stream[T]
- 合包(Concat):将 Stream[T] 合并成一个完整的 T。Stream[T] 中的每一“帧”是这个完整 T 的一部分。
Eino 流式编程的内涵
- 有的组件,天然支持分“帧”来输出,每次输出一个完整出参的一部分,即“流式”输出。流式输出完成后,需要下游把这些“帧”拼接(concat)成完整的出参。典型的例子,是 LLM。
- 有的组件,天然支持分“帧”来输入,接收到不完整的入参时,就能开始有意义的业务处理,甚至完成业务处理的过程。比如 react agent 中用来判断是调 tool 还是结束运行的 branch 里面,拿到 LLM 的流式输出,从第一个帧里面就可以通过判断 message 是否包含 tool call 来做出决策。
- 因此,一个组件,从入参角度看,有“非流式”入参和“流式”入参两种,从出参角度看,有“非流式”出参和“流式”出参两种。
- 组合起来,有四种可能的流式编程范式
| 函数名 | 模式说明 | 交互模式名称 | Lambda 构造方法 | 说明 |
| Invoke | 输入非流式、输出非流式 | Ping-Pong 模式 | compose.InvokableLambda() | |
| Stream | 输入非流式、输出流式 | Server-Streaming 模式 | compose.StreamableLambda() | |
| Collect | 输入流式、输出非流式 | Client-Streaming | compose.CollectableLambda() | |
| Transform | 输入流式、输出流式 | Bidirectional-Streaming | compose.TransformableLambda() |
单个组件角度的流式
Eino 是个 “component first” 的框架,组件可以独立使用。定组件接口的时候,需要考虑流式编程的问题吗?简单的答案是不需要。复杂的答案是“以业务真实场景为准”。
组件自身的业务范式
一个典型的组件,比如 Chat Model,Retriever 等,根据实际的业务语义定接口就行,如果实际上支持某种流式的范式,就实现那一种流式范式,如果实际上某种流式范式没有真正的业务场景,那就不需要实现。比如
- Chat Model,除了 Invoke 这种非流式的范式外,还天然支持 Stream 这种流式范式,因此 Chat Model 的接口中,实现了 Generate 和 Stream 两个接口。但是 Collect 和 Transform 没有对应的真实业务场景,所以就没有实现相应的接口:
type ChatModel interface {
Generate(ctx context.Context, input []*schema.Message, opts ...Option) (*schema.Message, error)
Stream(ctx context.Context, input []*schema.Message, opts ...Option) (
*schema.StreamReader[*schema.Message], error)
// other methods omitted...
}
- Retriever,除了 Invoke 这种非流式的范式外,另外三种流式范式都没有真实的业务场景,因此只实现了 Retrieve 一个接口:
type Retriever interface {
Retrieve(ctx context.Context, query string, opts ...Option) ([]*schema.Document, error)
}
组件具体支持的范式
| 组件名称 | 是否实现 Invoke | 是否实现 Stream | 是否实现 Collect | 是否实现 Transform |
| Chat model | yes | yes | no | no |
| Chat template | yes | no | no | no |
| Retriever | yes | no | no | no |
| Indexer | yes | no | no | no |
| Embedder | yes | no | no | no |
| Document Loader | yes | no | no | no |
| Document Transformer | yes | no | no | no |
| Tool | yes | yes | no | no |
Eino 官方组件中,除了 Chat Model 和 Tool 额外支持 stream 外,其他所有组件都只支持 invoke。组件具体介绍参见:[更新中]Eino: Components 抽象&实现
Collect 和 Transform 两种流式范式,目前只在编排场景有用到。
多个组件编排角度的流式
组件在编排中的流式范式
一个组件,单独使用时,入参和出参的流式范式是框定的,不可能超出组件定义的接口范围。
- 比如 Chat Model,入参只可能是非流式的 []Message,出参则可能是非流式的 Message 或者流式的 StreamReader[Message],因为 Chat Model 只实现了 Invoke 和 Stream 两个范式。
但是,一个组件,一旦处在多个组件组合使用的“编排”场景中,它的入参和出参就没那么固定了,而是取决于这个组件在编排场景中的“上游输出”和“下游输入”。比如 React Agent 的典型编排示意图:
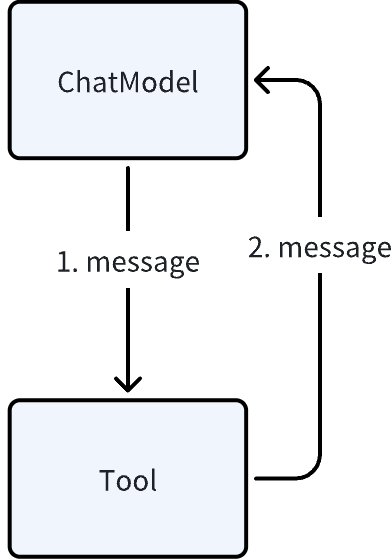
上图中,如果 Tool 是个 StreamableTool,也就是输出是 StreamReader[Message],则 Tool -> ChatModel 就可能是流式的输出。但是 Chat Model 并没有接收流式输入的业务场景,也没有对应的接口。这时 Eino 框架会自动帮助 ChatModel 补足接收流式输入的能力:
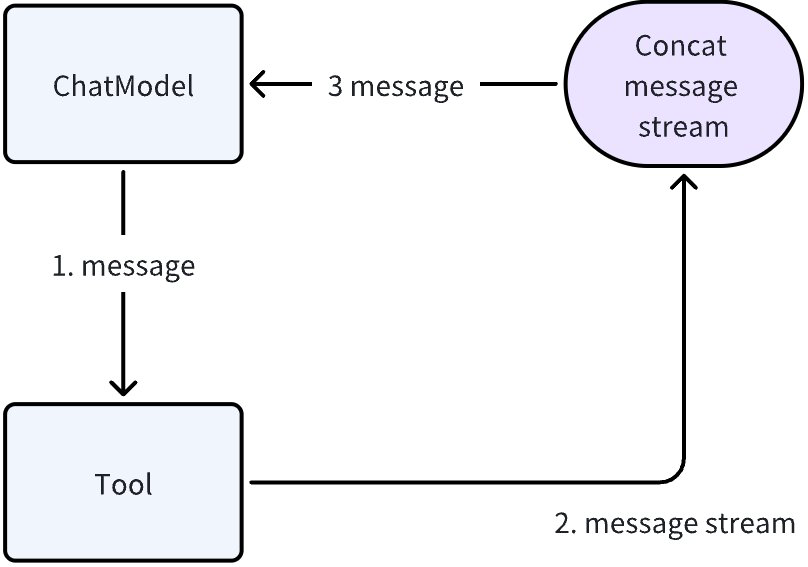
上面的 Concat message stream 是 Eino 框架自动提供的能力,即使不是 message,是任意的 T,只要满足特定的条件,Eino 框架都会自动去做这个 StreamReader[T] 到 T 的转化,这个条件是:在编排中,当一个组件的上游输出是 StreamReader[T],但是组件只提供了 T 作为输入的业务接口时,框架会自动将 StreamReader[T] concat 成 T,再输入给这个组件。
💡 框架自动将 StreamReader[T] concat 成 T 的过程,可能需要用户提供一个 Concat function。详见 Eino: 编排的设计理念 中关于“合并帧”的章节。
另一方面,考虑一个相反的例子。还是 React Agent,这次是一个更完整的编排示意图:
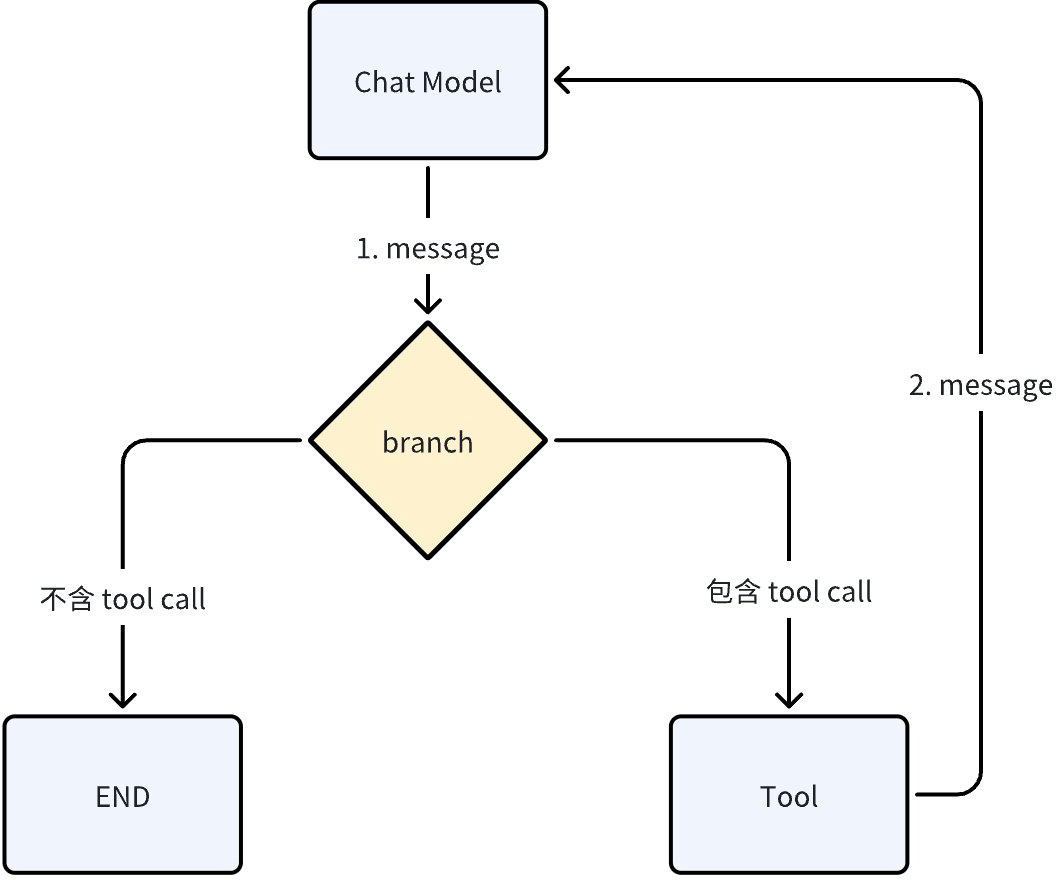
在上图中,branch 接收 chat model 输出的 message,并根据 message 中是否包含 tool call,来选择直接结束 agent 本次运行并将 message 输出,还是调用 Tool 并将调用结果再次给 Chat Model 循环处理。由于这个 Branch 可以通过 message stream 的首个帧就完成逻辑判断,因此我们给这个 Branch 定义的是 Collect 接口,即流式输入,非流式输出:
compose.NewStreamGraphBranch(func(ctx context.Context, sr *schema.StreamReader[*schema.Message]) (endNode string, err error) {
msg, err := sr.Recv()
if err != nil {
return "", err
}
defer sr.Close()
if len(msg.ToolCalls) == 0 {
return compose._END_, nil
}
return nodeKeyTools, nil
}
ReactAgent 有两个接口,Generate 和 Stream,分别实现了 Invoke 和 Stream 的流式编程范式。当一个 ReactAgent 以 Stream 的方式被调用时,Chat Model 的输出是 StreamReader[Message],因此 Branch 的输入是 StreamReader[Message],符合这个 Branch condition 的函数签名定义,不需要做任何的转换就可以运行。
但是,当这个 ReactAgent 以 Generate 的方式被调用时,Chat Model 的输出是 Message,因此 Branch 的输入也会是 Message,不符合 Branch Condition 的 StreamReader[Message] 的函数签名定义。这时,Eino 框架会自动将 Message 装箱成 StreamReader[Message],再传给 Branch,而这个 StreamReader 里面只会有一个帧。
💡 这种只有一个帧的流,俗称“假流”,因为它并没有带来流式的实际好处即“首包延迟低”,而是仅仅为了满足流式出入参接口签名的要求而做的简单装箱。
总结起来,就是:在编排中,当一个组件的上游输出是 T,但是组件只提供了 StreamReader[T] 作为输入的业务接口时,框架会自动将 T 装箱成 StreamReader[T] 的单帧流,再输入给这个组件。
编排辅助元素的流式范式
上面提到的 Branch,并不是一个可单独使用的组件,而是只在编排场景中才有意义的“编排辅助元素”,类似的仅编排场景有意义的“组件”,还有一些,详见下图:
| 组件名称 | 使用场景 | 是否实现 Invoke | 是否实现 Stream | 是否实现 Collect | 是否实现 Transform |
| Branch | 根据上游输出,在一组下游 Node 中动态选择一个 | yes | no | yes | no |
| StatePreHandler | Graph中,进入 Node 前修改 State 或/与 Input。可支持流式。 | yes | no | no | yes |
| StatePostHandler | Graph中,Node 完成后修改 State 或/与 Output。可支持流式 | yes | no | no | yes |
| Passthrough | 在并行情况下,为了打平每个并行分支的 Node 个数,可以给 Node 个数少的分支加 Passthrough 节点。Passthrough 节点的输入输出相同,跟随上游节点的输出或跟随下游节点的输入(预期应当相同)。 | yes | no | no | yes |
| Lambda | 封装官方组件未定义的业务逻辑。业务逻辑是哪种范式,就选择对应的那种流式范式来实现。 | yes | yes | yes | yes |
另外还有一种只有编排场景才有意义的“组件”,就是把编排产物作为一个整体来看待,比如编排后的 Chain,Graph。这些整体的编排产物,既可以作为“组件”来单独调用,也可以作为节点加入到更上级的编排产物中。
编排整体角度的流式
编排产物的“业务”范式
既然整体的编排产物,可以被看做一个“组件”,那从组件的视角可以提出问题:编排产物这个“组件”,有没有像 Chat Model 等组件那样的,符合“业务场景”的接口范式?答案是既“有”也“没有”。
- “没有”:整体而言,Graph,Chain 等编排产物,自身是没有业务属性的,只为抽象的编排服务的,因此也就没有符合业务场景的接口范式。同时,编排需要支持各种范式的业务场景。所以,Eino 中代表编排产物的 Runnable[I, O] 接口,不做选择也无法选择,提供了所有流式范式的方法:
type Runnable[I, O any] interface {
Invoke(ctx context.Context, input I, opts ...Option) (output O, err error)
Stream(ctx context.Context, input I, opts ...Option) (output *schema.StreamReader[O], err error)
Collect(ctx context.Context, input *schema.StreamReader[I], opts ...Option) (output O, err error)
Transform(ctx context.Context, input *schema.StreamReader[I], opts ...Option) (output *schema.StreamReader[O], err error)
}
- “有”:具体而言,某一个具体的 Graph、Chain,一定是承载了具体的业务逻辑的,因此也就一定有适合那个特定业务场景的流式范式。比如类似 React Agent 的 Graph,匹配的业务场景是 Invoke 和 Stream,因此这个 Graph 在调用时,符合逻辑的调用方式是 Invoke 和 Stream。虽然编排产物本身接口 Runnable[I, O] 中有 Collect 和 Transform 的方法,但是正常的业务场景不需要使用。
编排产物内部各组件在运行时的范式
从另一个角度看,既然编排产物整体可以被看做“组件”,那“组件”必然有自己的内部实现,比如 ChatModel 的内部实现逻辑,可能是把入参的 []Message 转化成各个模型的 API request,之后调用模型的 API,获取 response 后再转化成出参的 Message。那么类比的话,Graph 这个“组件”的内部实现是什么?是数据在 Graph 内部各个组件间以用户指定的流转方向和流式范式来流转。其中,“流转方向”不在当前讨论范围内,而各组件运行时的流式范式,则由 Graph 整体的触发方式决定,具体来说:
如果用户通过 Invoke 来调用 Graph,则 Graph 内部所有组件都以 Invoke 范式来调用。如果某个组件,没有实现 Invoke 范式,则 Eino 框架自动根据组件实现了的流式范式,封装出 Invoke 调用范式,优先顺位如下:
- 若组件实现了 Stream,则将 Stream 封装成 Invoke,即自动 concat 输出流。

- 否则,若组件实现了 Collect,则将 Collect 封装成 Invoke,即非流式入参转单帧流。

- 如果都没实现,则必须实现 Transform,将 Transform 封装成 Invoke,即入参转单帧流,出参 concat。
![]()
如果用户通过 Stream/Collect/Transform 来调用 Graph,则 Graph 内部所有组件都以 Transform 范式来调用。如果某个组件,没有实现 Transform 范式,则 Eino 框架自动根据组件实现了的流式范式,封装出 Transform 调用范式,优先顺位如下:
- 若组件实现了 Stream,则将 Stream 封装成 Transform,即自动 concat 输入流。
![]()
- 否则,若组件实现了 Collect,则将 Collect 封装成 Transform,即非流式出参转单帧流。
![]()
- 如果都没实现,则必须实现 Invoke,将 Invoke 封装成 Transform,即入参流 concat,出参转单帧流
![]()
结合上面穷举的各种案例,Eino 框架对 T 和 Stream[T] 的自动转换,可以总结为:
- T -> Stream[T]: 将完整的 T 装箱为单帧的 Stream[T]。非流式变假流式。
- Stream[T] -> T: 将 Stream[T] Concat 为完整的 T。当 Stream[T] 不是单帧流时,可能需要提供针对 T 的 Concat 方法。
看了上面的实现原理,可能会有疑问,为什么对 graph 的 Invoke,会要求所有内部组件都以 Invoke 调用?以及为什么对 graph 的 Stream/Collect/Transform,会要求所有内部组件都以 Transform 调用?毕竟,可以举出一些反例:
- A, B 两个组件编排为一个 Chain,以 Invoke 调用。其中 A 的业务接口实现了 Stream,B 的业务接口实现了 Collect。这时 graph 内部组件的调用范式有两个选择:
- A 以 stream 调用,B 以 collect 调用,整体的 Chain 依然是 Invoke 语义,同时保留了真流式的内部语义。即 A 的输出流不需要做 Concat,可以实时的输入到 B 中。
- 目前 Eino 的实现,A、B 都以 Invoke 调用,需要把 A 的输出流 Concat,并把 B 的输入做成假流式。失去了真流式的内部语义。
- A,B 两个组件编排为一个 Chain,以 Collect 调用。其中 A 实现了 Transform 和 Collect,B 实现了 Invoke。两个选择:
- A 以 Collect 调用,B 以 Invoke 调用:整体还是 Collect 的语义,不需要框架做任何的自动转化和装箱操作。
- 目前 Eino 的实现,A、B 都以 Transform 调用,由于 A 的业务接口里实现了 Transform,因此 A 的输出和 B 的输入都可能是真流式,而 B 的业务接口里只实现了 Invoke,根据上面的分析,B 的入参会需要由真流式 concat 成非流式。这时就需要用户额外提供 B 的入参的 concat 函数,这本可以避免。
上面两个例子,都可以找到一个明确的、与 Eino 的约定不同的,但却更优的流式调用路径。但是,当泛化到任意的编排场景时,很难找到一个明确定义的、与 Eino 的约定不同的、却总是更优的普适的规则。比如,A->B->C,以 Collect 语义调用,是 A->B 的时候 Collect,还是 B->C 的时候 Collect?潜在的因素有 A、B、C 具体实现的业务接口,可能还有“尽量多的使用真流式”的判断,也许还有哪个参数实现了 Concat,哪个没有实现。如果是更复杂的 Graph,需要考虑的因素会快速增加。在这种情况下,即使框架能定义出一套明确的、更优的普适规则,也很难解释清楚,理解和使用成本会很高,很可能已经超过了这个新规则实际带来的好处。
综上,我们可以说,Eino 编排产物内部各组件在运行时的范式,是 By Design 的,明确如下:
- 整体以 Invoke 调用,内部各组件均以 Invoke 调用,不存在任何流式的过程。
- 整体以 Stream/Collect/Transform 调用,内部各组件均以 Transform 调用,当出现 Stream[T] -> T 的 concat 过程时,可能需要额外提供 T 的 concat function。