Getting Started With Kitex's Practice: Performance Testing Guide
Projects:
On September 8, 2021, ByteDance announced the launch of CloudWeGo open source project. CloudWeGo is a set of microservice middleware developed by ByteDance with high performance, strong scalability and stability. It focuses on microservice communication and governance, and meets the demands of different services in various scenarios. CloudWeGo currently has 4 Repos: Kitex, Netpoll, Thriftgo and netpoll-http2, featuring the RPC framework – Kitex and the network library – Netpoll.
Recently, ByteDance Service Framework Team officially announced the open source of CloudWeGo. It includes the Golang microservice RPC framework – Kitex, which has been deeply used in Douyin and Toutiao.
This article aims to share the scenarios and technical issues that developers need to know when stress testing Kitex. These guides will help users adjust and optimize Kitex to better match their business needs, and maximize Kitex’s performance in real RPC scenarios. Users can also refer to the official stress test project – kitex-benchmark for more details.
The Characteristics of Microservice Scenario
Kitex was born in ByteDance’s large-scale microservices architecture practice. The scenario it is aimed at is naturally a microservices scenario. Therefore, the following will first introduce the characteristics of microservices, so that developers can understand Kitex’s design thinking in depth.
- RPC Communication Model
The communication between microservices is usually based on PingPong model. So, in addition to the conventional throughput performance index, developers also need to consider the average latency of each RPC.
- Complex Call Chain
An RPC call often requires multiple microservices to collaborate, and downstream services have their own dependencies, so the entire call chain will be a complex network structure.
In this kind of complex call chains, the latency fluctuation of one intermediate node may be transmitted to the entire chain,resulting in an overall timeout. When there are many nodes on the chain, even if the fluctuation probability of each node is very low, the timeout probability that eventually converges on the chain will be magnified. Therefore, the latency fluctuation of a single service, notably P99, is also a key indicator that has a significant impact on online services.
- Size of Data Package
Although the size of transmitted data packages depends on the actual business scenario, the internal statistics of ByteDance found that most online requests are small packages (<2KB). So we focused on optimizing the performance in the small data package scenarios while taking the large package scenarios into account.
Stress Test for Microservice Scenarios
Determine Stress Test Objects
Measuring the performance of an RPC framework requires consideration from two perspectives: Client and Server. In large-scale business architectures, upstream clients are not necessarily using the same frameworks as downstream, and same goes to the downstream services scheduled by developers. The situation becomes more complicated when Service Mesh is involved.
Some stress test projects often generate performance data for the entire framework by mixing Client and Server processes, which is likely to be inconsistent with the actual online operation.
If you want to stress test Server, you should give Client as many resources as possible to push Server to its limit, and vice versa. If both Client and Server are only provided 4-core CPUs for stress tests, it will be impossible for developers to determine the performance data is referring to either Client or Server. Thus, the test result will not have practical value for online services.
Alignment of Connection Model
Conventional RPCs have three major connection models:
- Short connection: Each request creates a new connection and closes the connection immediately after the return is received.
- Persistent connection pool: A single connection can process only one complete request & return at once.
- Connection multiplexing: A single connection can process multiple requests & returns asynchronously at the same time.
Each type of connection model is not absolutely good or bad, it depends on the actual usage scenario. Although connection multiplexing generally performs the best, the application must rely on the protocol being able to support package serial numbers, and some older framework services may not support multiplexing calls.
In order to ensure maximum compatibility, Kitex initially used short connections on the Client side by default, while other mainstream open source frameworks used connection multiplexing by default. It resulted in large performance data deviations for some users when stress testing with default configuration.
Later, in order to accommodate the common scenario of open source users, Kitex supported persistent connection by default in v0.0.2.
Alignment of Serialization Strategy
For RPC frameworks, regardless of service governance, the computation overhead is mainly generated in serialization and deserialization.
Kitex uses the Go protobuf library to serialize Protobuf. And for serialization of Thrift, Kitex has specific performance optimization, which is introduced in the blog post on our official web.
Most of the current open source frameworks support Protobuf in preference, and some built-in Protobuf are actually gogo/protobuf versions with performance optimizations. However, gogo/protobuf is currently at risk of maintenance absence. Therefore, due to maintainability concerns, we decided to use the official protobuf library only. Certainly, we will plan to optimize Protobuf in the future.
Use Exclusive CPU
Although multiple processes would usually utilize the CPU capability at the same time for online applications. But in stress test scenarios, both Client and Server processes are extremely busy. Sharing the CPU will result in a large number of context switching, which makes the output data less reliable and prone to large fluctuations.
Therefore, we recommend that the Client and Server processes should be isolated on different CPUs or different exclusive machines. If you want to further avoid the impact of other processes, you can add the nice -n -20 command to adjust the scheduling priority of the stress testing process.
In addition, if possible, using physical machines makes the test results more precise and reproducible compared to using virtual machines on cloud platforms.
Performance Data Demonstration
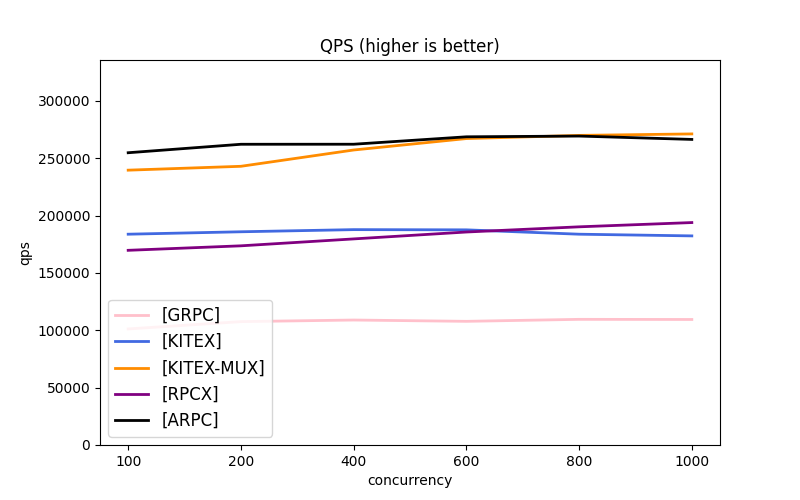
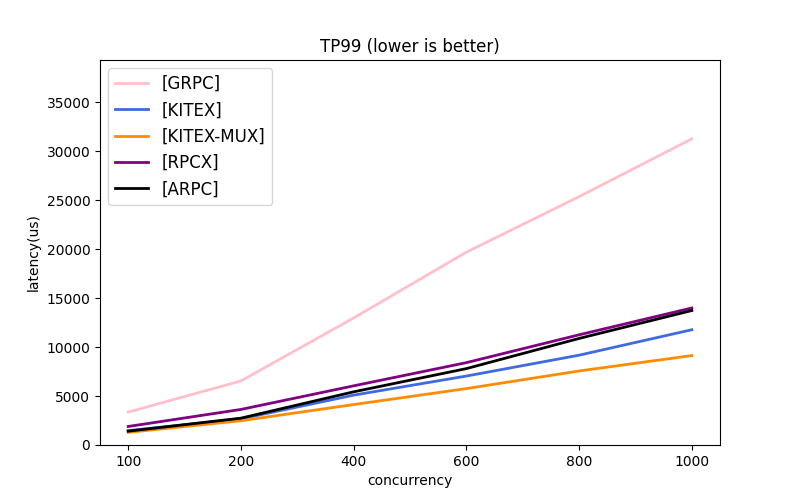
On the premise of meeting the above requirements, we compared the stress test results of multiple frameworks using Protobuf. The stress test source code can be found in kitex-benchmark repo. When Server is fully loaded, P99 Latency of Kitex in connection pool mode is the lowest of all frameworks. In multiplexing mode, Kitex also performs well in each indicator.
Configuration
- Client 16 CPUs,Server 4 CPUs
- 1KB Request Package Size, Echo Scenario
Reference Data
- KITEX: Connection Pool Model (Default Setting)
- KITEX-MUX: Connection Multiplexing
- Connection Multiplexing for all other Frameworks
Summary
Each mainstream Golang open source RPC framework actually has its own focus in terms of design goals: some focus on generality, some on scenarios with light business logic like Redis, some on throughput performance, and some on P99 latency.
In the daily iteration of ByteDance’s business, it is common for a feature to cause one indicator to rise and another indicator to decline. Therefore, Kitex was more inclined to solve various problems in large-scale microservice scenarios at the beginning of its design.
Since the launch of Kitex, we have received a large amount of self-testing data from our users. We appreciate the community for their attention and support. We also encourage developers to use the testing guide provided in this article, and select appropriate tools for their own scenarios. For more questions, please make an Issue on GitHub.