ByteDance Practices on Go Network Library
Projects:
This article is excerpted from the ByteDance Architecture Practice series.
“ByteDance Architecture Practice” is a series of articles produced by the technical teams and experts from the ByteDance Architecture Team, to share the team’s practical experience and lessons learnt from the development of infra-architecture, for the purpose of enhancing communication and growth of the developers.
As an important part of R&D system, RPC framework carries almost all service traffics. This paper will briefly introduce the design and practice of the ByteDance in-house developed network library – Netpoll, as well as the problems and solutions that arise during our practices. This article can be used as a reference to help the tech-community’s further practices and experiments.
Preface
As an important part of the R&D system, RPC framework carries almost all service traffics. As Golang is used more and more widely in ByteDance, the business has higher requirements on its framework. However, the “Go net” library cannot provide sufficient performance and control to support the business, notably inability to perceive the connection state, low utilization due to the large number of connections, and inability to control the number of goroutines. In order to take full control of the network layer, it’s necessary to make some exploration prospectively, and finally empower the business. The Service Framework Team launched a new self-developed network library – “Netpoll” based on “epoll”, and developed a new-generation Golang framework – “Kitex” based on “Netpoll”.
Since there are many articles discussing the principles of “epoll”, this article will briefly introduce the design of “Netpoll” only. We’ll then try to review some of our practices regarding “Netpoll”. Finally, we’ll share a problem we encountered during our practices and how we solved it. In the meantime, we welcome more peers who are interested in Golang and Go framework to join us!
Design of the New Network Library
Reactor - Event Monitoring and the Core of Scheduling
The core of “Netpoll” is the event monitoring scheduler – “Reactor”, which uses “epoll” to monitor the “File Descriptor (fd)” of the connection and triggers the read, write and close events on the connection through the callback mechanism.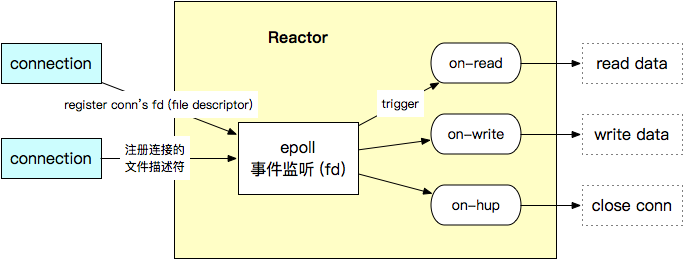
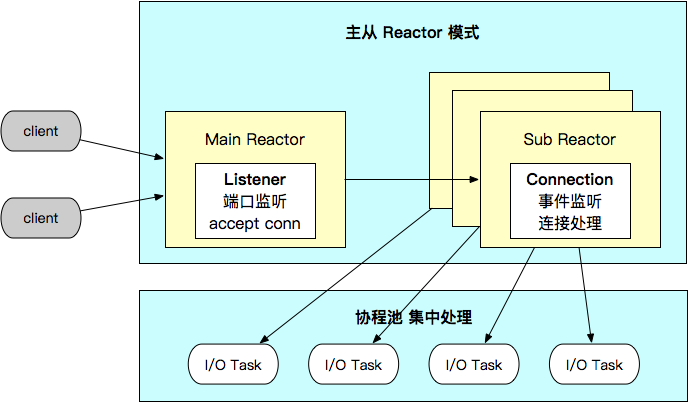
Server - MainReactor & SubReactor Implementation
Netpoll combines Reactors in a 1: N master-slave pattern:
- “MainReactor” mainly manages the “Listener”, and is responsible for monitoring ports and establishing new connections.
- The “SubReactor” manages the “Connection”, listens all assigned connections, and submits all triggered events to the goroutine pool for processing.
- “Netpoll” supports “NoCopy RPC” by introducing active memory management in I/O tasks and providing an “NoCopy” invocation interface to the upper layer.
- Add a goroutine pool to centrally process I/O tasks, reduce the number of goroutines and scheduling overhead.
Client - Shares the Capability of Reactor
SubReactor is shared between the client and server. Netpoll implements “Dialer” and provides the function for establishing connections. On the client, similar to “net.Conn”, Netpoll provides underlying support for “write -> wait read callback”.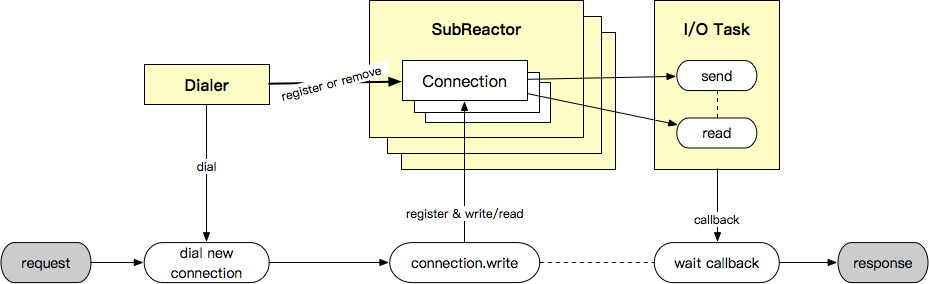
Nocopy Buffer
Why Nocopy Buffer?
As mentioned earlier, the way epoll is triggered affects the design of I/O and buffer, which can be generally divided into two approaches:
- Level Trigger (LT). It is necessary to complete I/O actively after the event is triggered, and provides buffers directly to the upper code.
- Edge Trigger (ET). You can choose to manage the event notification only (e.g. go net), with the upper layer code for I/O completion and buffers management.
Both ways have their advantages and disadvantages. “Netpoll” adopts the first strategy, which has better timeliness and higher fault tolerance rate. Active I/O can centralize memory usage and management, provide nocopy operation, and reduce GC. In fact, some popular open-source network libraries, such as “easygo”, “evio”, “gnet”, etc. are also designed in this way.
However, using LT also brings another problem, namely the additional concurrency overhead caused by the underlying active I/O and the concurrent buffer operations by the upper code. For example, there are concurrent read and write when I/O read(data)/write(buffer) and the upper code reads the buffer, vice versa. In order to ensure data correctness and avoid lock contention, existing open-source network libraries usually adopt synchronous processing of buffer (“easygo”, “evio”) or provide a copy of buffer to the upper layer code (“gnet”), which are not suitable for business processing or have considerable copy overhead.
On the other hand, common buffer libraries such as “bytes”, “bufio”, and “ringbuffer” have problems such as “growth” requiring copy of data from the original array; capacity can only be expanded but can’t be reduced; occupying a large amount of memory etc. Therefore, we hope to introduce a new form of buffer to solve the two problems above.
The Design and Advantages of Nocopy Buffer
Nocopy Buffer is implemented based on linked-list of array. As shown in the figure below, we abstract []byte array into blocks and combine blocks into Nocopy Buffer in the form of a linked list. Meanwhile, reference counting mechanism, Nocopy API and object pool are introduced.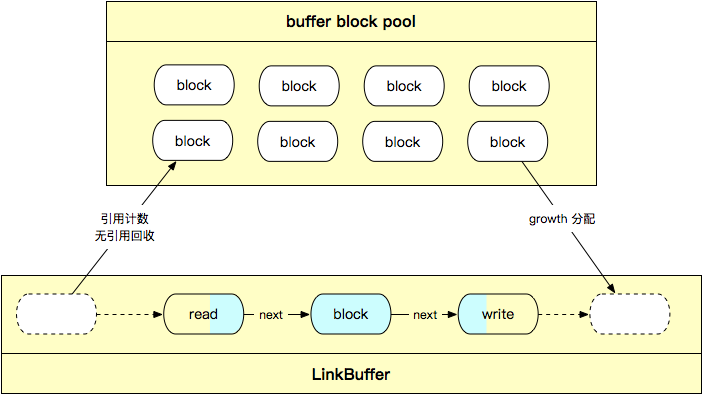
Nocopy Buffer has the following advantages over some common buffer libraries like “bytes”, “bufio”, and “ringbuffer”:
- Read and write in parallel without lock, and supports stream read/write with nocopy
- Read and write operate the head pointer and tail pointer separately without interfering with each other.
- Efficient capacity expansion and reduction
- For capacity expansion, you can add new blocks directly after the tail pointer without copying the original array.
- For capacity reduction, the head pointer directly releases the used block node to complete the capacity reduction. Each block has an independent reference count, and when the freed block is no longer referenced, the block node is actively reclaimed.
- Flexible slicing and splicing of buffer (the characteristic of linked list)
- Support arbitrary read slicing (nocopy), and the upper layer code can process data stream slicing in parallel with nocopy by reference counting GC, regardless of the lifecycle.
- Support arbitrary splicing (nocopy). Buffer write supports splicing block after the tail pointer, without copy, and ensuring that data is written only once.
- Nocopy Buffer is pooled to reduce GC
- Treat each []byte array as a block node, and build an object pool to maintain free blocks, thus reuse blocks, reduce memory footprint and GC. Based on the Nocopy Buffer, we implemented Nocopy Thrift, so that the codec process allocates zero memory with zero copy.
Connection Multiplexing
RPC calling is usually in the form of short connection or persistent connection pool, and each call is bound to one connection. Therefore, when the scale of upstream and downstream is large, the number of existing connections in the network increases in the speed of MxN, which brings huge scheduling pressure and computing overhead, and makes service governance difficult. Therefore, we want to introduce a mechanism for “parallel processing of calls on a single persistent connection” to reduce the number of connections in the network. This mechanism is called connection multiplexing.
There are some existing open-source connection multiplexing solutions. But they are limited by code level constraints. They all require copy buffer for data subcontracting and merging, resulting in poor performance. Nocopy Buffer, with its flexible slicing and splicing, well supports data subcontracting and merging with nocopy, making it possible to achieve high-performance connection multiplexing schemes.
The design of Netpoll-based connection multiplexing is shown in the figure below. We abstract the Nocopy Buffer(and its sharding) into virtual connections, so that the upper layer code retains the same calling experience as “net.Conn”. At the same time, the data on the real connection can be flexibly allocated to the virtual connection through protocol subcontracting in the underlying code. Or send virtual connection data through protocol encoding.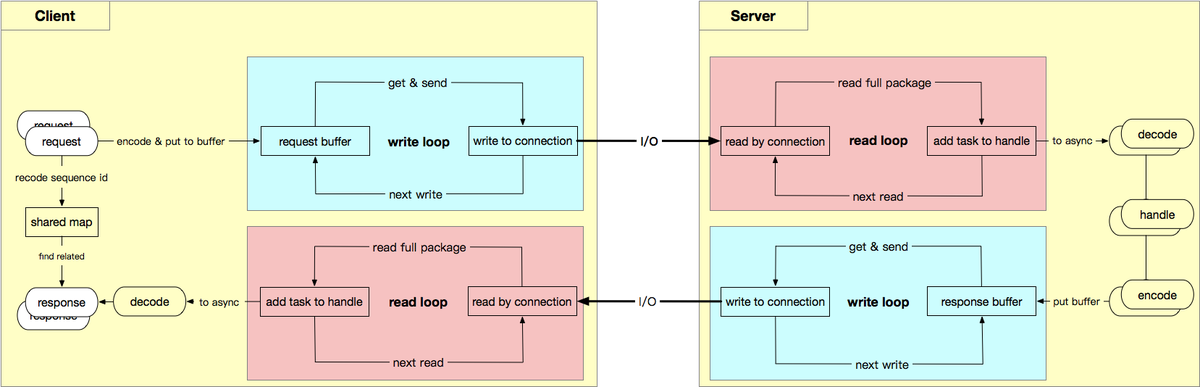
The connection multiplexing scheme contains the following core elements:
- The virtual connection
- It is essentially a “Nocopy Buffer”, designed to replace real connections and avoid memory copy.
- The upper-layer service logic/codec is executed on the virtual connection, and the upper-layer logic can be executed in parallel asynchronously and independently.
- Shared map
- Shared locking is introduced to reduce the lock intensity.
- The Sequence ID is used to mark the request on the caller side and the shared lock is used to store the callback corresponding to the ID.
- After receiving the response data, find the corresponding callback based on the sequence ID and execute it.
- Data subcontracting and encoding
- How to identify the complete request-response data package is the key to make the connection multiplexing scheme feasible, so the protocol needs to be introduced.
- The “Thrift Header Protocol” is used to check the data package integrity through the message header, and sequence ids are used to mark the corresponding relations between request and response.
ZeroCopy
“ZeroCopy” refers to the ZeroCopy function provided by Linux. In the previous chapter, we discussed nocopy of the service layer. But as we know, when we call the “sendmsg” system-call to send a data package, actually there is still a copy of the data, and the overhead of such copies is considerable when the data packages are large. For example, when the data package has the size of 100M, we can see the following result: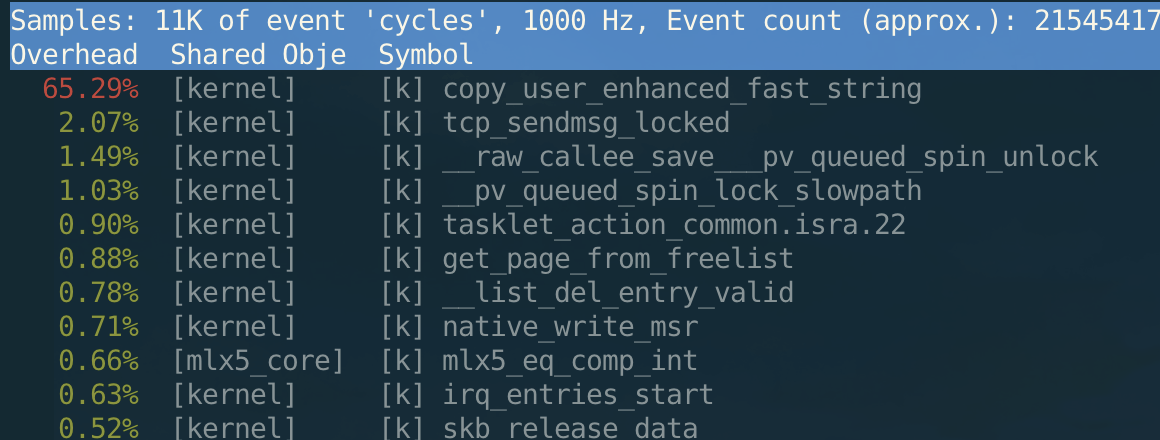
The previous example is merely the overhead of tcp package sending. In our scenario, most services are connected to the “Service Mesh”. Therefore, there are three copies in a package sending: Service process to kernel, kernel to sidecar, sidecar to kernel. This makes the CPU usage caused by copying especially heavy for services demanding large package transactions, as shown in the following figure: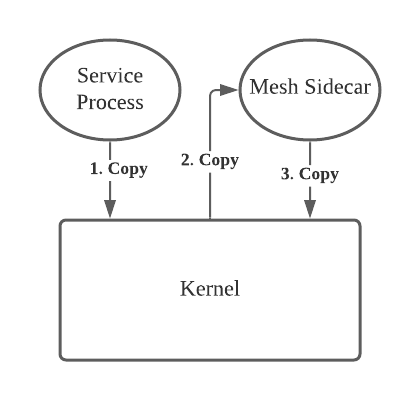
To solve this problem, we chose to use the ZeroCopy API provided by Linux (send is supported after 4.14; receive is supported after 5.4). But this introduces an additional engineering problem: the ZeroCopy send API is incompatible with the original call method and does not coexist well. Here’s how ZeroCopy Send works: After the service process calls “sendmsg”, “sendmsg” records the address of the “iovec” and returns it immediately. In this case, the service process cannot release the memory, and needs to wait for the kernel to send a signal indicating that an “iovec” has been successfully sent before it can be released via “epoll”. Since we don’t want to change the way the business side uses it, we need to provide a synchronous sending and receiving interface to the upper layer, so it is difficult to provide both ZeroCopy and non-Zerocopy abstraction based on the existing API. Since ZeroCopy has performance degradation in small package scenarios, this is not the default option.
Thus, the ByteDance Service Framework Team collaborated with the ByteDance Kernel Team. The Kernel Team provided the synchronous interface: when “sendmsg” is called, the kernel listens and intercepts the original kernel callback to the service, and doesn’t let “sendmsg” return values until the callback is complete. This allows us to easily plug in “ZeroCopy send” without changing the original model. Meanwhile, the ByteDance Kernel Team also implements ZeroCopy based on Unix domain socket, which enables zero-copy communication between service processes and Mesh sidecar.
After using “ZeroCopy send”, we can see that the kernel is no longer occupied by copy through perf: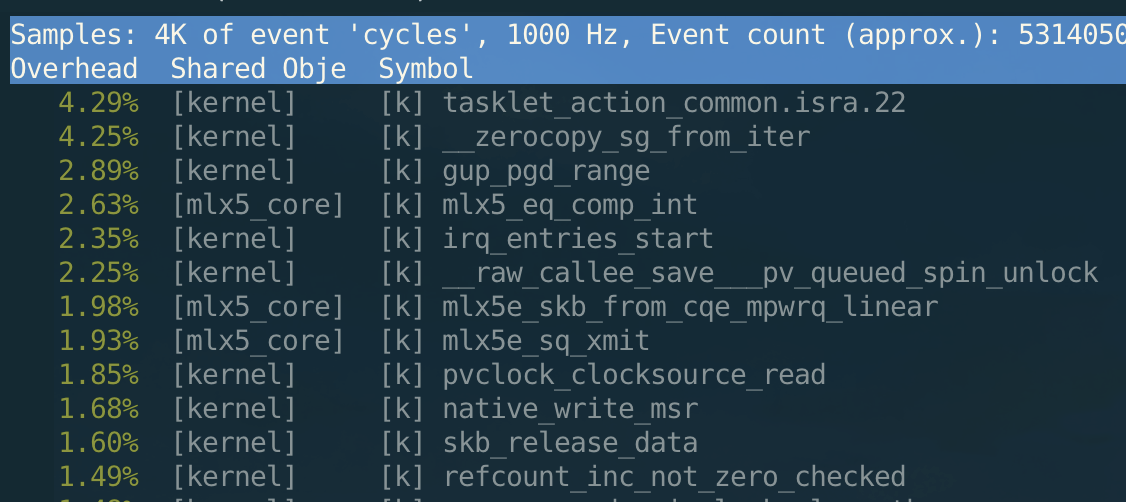
In terms of CPU usage, ZeroCopy can save half the cpu of non-ZeroCopy in large package scenarios.
Delay Caused By Go Scheduling
PS: This problem has been fixed in the new version of Netpoll. The solution is to set
EpollWaittimeout parameter to 0 and actively give up the execution right to optimize the goroutine scheduling to improve the efficiency.
In our practice, we found that although our newly written “Netpoll” outperformed the “Go net” library in terms of avg delay, it was generally higher than the “Go net” library in terms of p99 and max delay, and the spikes would be more obvious, as shown in the following figure (Go 1.13, Netpoll + multiplexing in blue, Netpoll + persistent connection in green, Go net library + persistent connection in yellow):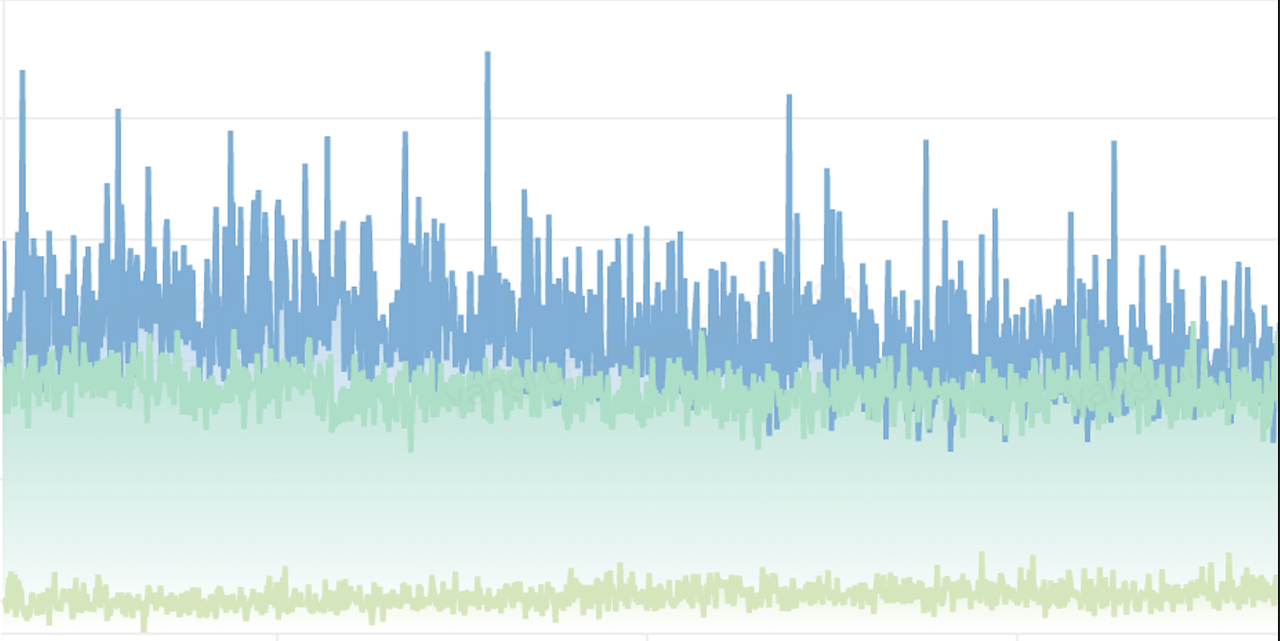
We tried many ways to improve it, but the outcomes were unsatisfactory. Finally, we locate that the delay was not caused by the overhead of “Netpoll” itself, but by the scheduling of Go, for example:
- In “Netpoll”, the “SubReactor” itself is also a “goroutine”, which is affected by scheduling and cannot be guaranteed to be executed immediately after the “EpollWait” callback, so there would be a delay here.
- At the same time, since the “SubReactor” used to handle I/O events and the “MainReactor” used to handle connection listening are “goroutines” themselves, it is actually impossible to ensure that these reactors can be executed in parallel under multi-kernel conditions. Even in the most extreme cases, these reactors may be under the same P, and eventually become sequential execution, which cannot take full advantage of multi-kernel;
- After “EpollWait callback”, I/O events are processed serially in the “SubReactor”, so the last event may have a long tail problem.
- In connection multiplexing scenarios, since each connection is bound to a “SubReactor”, the delay is entirely dependent on the scheduling of the “SubReactor”, resulting in more pronounced spikes. Because Go has specific improvements for the net library in runtime, the net library will not have the above situation. At the same time, the net library is also a “goroutine-per-connection” model, so it ensures that requests can be executed in parallel without interfering with each other.
For the above problems, we have two solutions at present:
- Modify the Go runtime source code, register a callback in the Go runtime, call EpollWait each time, and pass the fd to the callback execution;
- Work with the ByteDance Kernel Team to support simultaneous batch read/write of multiple connections to solve sequential problems. In addition, in our tests, Go 1.14 reduces the latency slightly lower and smoother, but the max QPS that can be achieved is lower. I hope our ideas can provide some references to peers in the industry who also encountered this problem.
Postscript
We hope the above sharing can be helpful to the community. At the same time, we are accelerating the development of “Netpoll” and “Kitex” – a new framework based on “Netpoll”. You are welcome to join us and build Golang ecology together!